How to Build a Large Language Model: Step-by-Step Guide

Want to know more? — Subscribe
Today, building a large language model marks a significant step forward, reshaping how we engage with technology. At its heart is the concept of language models designed to understand, interpret, and generate human language. The process of creating a large language model integrates the nuances of language with the computational power of modern technology.
In this article, Softermii explores the basics of large language models, their development journey, and factors that impact their cost. The impact of these models extends beyond tech industry applications to influence various aspects of daily life and work. They enhance user experience, automate complex tasks, and open new possibilities in human-computer interaction.

What is a Large Language Model?
A large language model, or LLM, is an advanced form of AI designed to understand, generate, and interact with human language. Unlike their predecessors, these models are not limited to rule-based language interpretations. Instead, they offer dynamic, flexible, and often detailed responses. This ability comes from being trained on diverse text sets, allowing them to grasp different linguistic styles, dialects, and jargon.
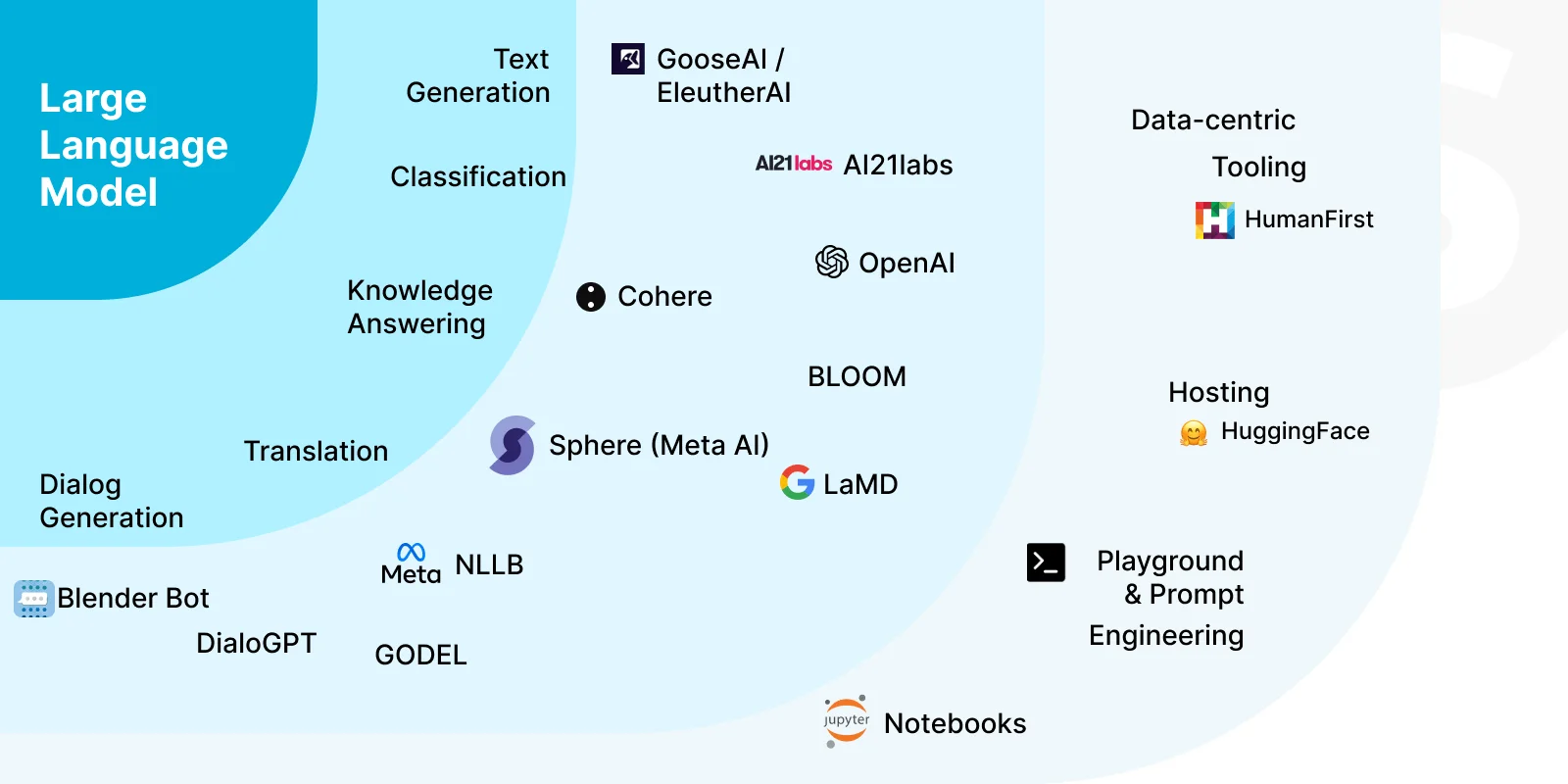
At their core, LLMs analyze the input and predict the most likely next word or phrase based on the context and patterns they've learned. Building large language models marks a major achievement in the AI and natural language processing industry.
Their creation has paved the way for more sophisticated and natural machine-human interactions. They are pivotal in language translation, content generation, and sentiment analysis. Today, you can even find generative AI in healthcare or financial services.
Core Concepts in Language Modeling
Several core concepts form the foundation of these sophisticated systems. Their integration marks a significant stride in the journey towards more advanced and human-like AI. This section covers three fundamental aspects: natural language processing, machine learning, and the application of deep learning.
Defining Natural Language Processing (NLP)
Natural language processing stands at the intersection of computer science, AI, and linguistics. It aims to enable computers to understand, interpret, and generate human language in a valuable and meaningful way.

NLP is crucial for developing applications that need human-computer interaction. It's also pivotal in enhancing the accessibility and efficiency of technology in processing human language. For instance, NLP allows machines to perform translation, sentiment analysis, and question-answering tasks.
The Role of Machine Learning in Language Models
Machine learning involves training computational models on large datasets to recognize patterns and make predictions or decisions. In the context of language models, ML algorithms are trained on large amounts of text data. Through this process, models learn the intricacies of language: grammar, syntax, and context. They become more dynamic, context-aware, and efficient in language understanding and generation. ML models can forecast the likelihood of a word sequence, helping in auto-completion, code generation, and language translation.
Understanding Deep Learning in the Context of NLP
A subset of machine learning, deep learning, has been instrumental in advancing NLP. It involves neural networks with multiple layers that can learn and make smart decisions independently.

In NLP, deep learning models, based on architectures like recurrent neural networks and transformers, can effectively process sequential data. They have become ideal for language generation, sentiment analysis, and syntactic parsing.
Steps to Building a Large Language Model
Building a large language model involves a multi-faceted and intricate process. Each step of making a large language model is critical, from planning to implementation. Their careful execution ensures the development of a model that aligns with the intended applications and ethical standards. Here's an overview of the key stages involved in this process:
Planning the Large Language Model
In this initial phase, the focus is on defining the scope and purpose of the LLM. It means outlining the model's objectives, target applications, and user base. This information sets the direction for the language processing capabilities the model will have.
The data source identification determines the quality and diversity of the training material. It could often range from web content to specific domain literature.
Additionally, it's important to consider the computational resources required, such as estimating processing power and storage, which are substantial for LLMs.
Data Collection and Preparation
In this phase, diverse datasets are collected. The approach depends on the model's scope, ensuring a wide range of language structures and idioms.
Then, data must be cleaned and preprocessed to make it suitable for training the model. It often involves removing irrelevant content, correcting errors, and formatting.
It's crucial to guarantee the quality and diversity of the data to avoid biases. It also helps to ensure the LLM's applicability across various contexts and user groups.
Designing the Language Model Architecture
The choice of generative AI tech stack and neural network framework is a critical decision at this point and should be based on the model's specific needs.
Designing the model architecture requires balancing its complexity against the desired performance level. Overly complex models need significant computational resources without proportional performance improvements.

Training the Model
The training process is where the model learns from the data. Data scientists start feeding the prepared dataset into the model, initiating this process.

Batch processing and optimization algorithms are often employed to enhance the procedure. It remains continuously monitored to ensure that the model is learning as intended. This stage is resource-intensive, often requiring adjustments and optimizations as the model evolves.
Fine-tuning and Optimization
After initial training, the model is often fine-tuned on more specific tasks or datasets. This approach improves its accuracy and relevance in particular contexts. For example, LLM becomes better at understanding specific jargon or accents.

Hyperparameter optimization means experimenting with settings like learning rates, dropout rates, or batch sizes. They help to find the optimal combination for the model's performance.
The use of pre-trained models enables a reduction in the required training resources, providing a solid foundation for the model to build upon
Testing
Comprehensive testing is crucial to ensure the model's reliability and accuracy of the large language model. This process includes various forms of validation, for example:
- performance testing evaluates accuracy, speed, and efficiency, ensuring the model meets processing standards.
- validation testing assesses the model's ability to generalize from training data to real-world scenarios;
- stress testing observes how the model behaves under extreme conditions, identifying its robustness;
- user acceptance testing gathers feedback to assess the model's alignment with user expectations;
- ethical and bias testing evaluates the model for biases and ethical implications;
- security and compliance testing ensure the model's security and adherence to regulations;
- iterative testing is an ongoing process throughout development to refine and improve the model based on feedback from each test.

Implementing the Language Model
After performance checks, the model can be integrated into different applications or platforms. This stage requires careful planning for scalability, compatibility, and security. Thus, the model can fit into different software environments or be adapted for specific user interfaces.
Monitoring and updates are crucial to maintain the model's relevance and effectiveness. It is especially important given the dynamic nature of language and AI advancements.
Technical Documentation
In-depth documentation covers every aspect of creating the large language model and its operational use. It explains the functionalities, limitations, and guidelines for effective usage and further development.
How Much Does it Cost to Create a Large Language Model?
The cost of building large language models depends on several factors. These expenses also involve resource allocation and time investment. Understanding these factors is crucial for budgeting and planning purposes. Here's a breakdown of the key elements that influence the overall cost of making a custom LLM:
Hardware and Infrastructure Costs
The foundation of LLM development is robust hardware and infrastructure. This aspect often constitutes a significant part of the budget.
Costs of Servers, GPUs, and Other Hardware. High-performance servers and GPUs are central to training LLMs. The cost of this hardware depends on the model's scale and the training duration.
Impact of Cloud Computing Services on Costs. Cloud computing from Amazon AWS or Google offers an alternative to physical hardware, potentially reducing upfront costs. But remember that these services operate on a subscription or usage-based model. Thus, they can become expensive for projects with extensive data processing and storage needs.

Data Acquisition and Processing Expenses
The data quality and quantity directly impact the effectiveness of an LLM, and acquiring and processing it incur significant expenses.
Financial Implications of Acquiring Large Datasets. The cost of data acquisition varies widely. While there are free public datasets, specific types of data or proprietary datasets can be costly. The volume of data required for an LLM also adds to the expense.
Costs Associated with Cleaning and Preparing Data. The process of data cleaning and preparation requires notable computational resources and time. Formatting, standardizing, and removing biases from the data can be labor-intensive and pricey.
Human Resources and Expertise
The expertise and skills of the development team are pivotal in creating an effective LLM.
Hiring Experts for Development and Maintenance. When making a large language model, you need a team of skilled professionals. You must find experts in data science, machine learning engineers, and NLP specialists with proficiency in Python. Retaining such talent can be a major cost factor, especially given the high demand for these skills in the tech industry.
Training Costs for AI Specialists. Beyond salaries, there are costs associated with training and upskilling employees. Keep your team updated with the latest AI and machine learning technology advancements.
Conclusion
The synergy between NLP, machine learning, and deep learning has paved the way for more advanced language models. Each stage of building a large language model is interdependent and critical to the success of your project. They ensure your model can effectively perform complex language processing tasks.
The potential of large language models is boundless, from enhancing communication to automating complex tasks in enterprises. Now is the right time to harness the power of LLMs. With Softermii, you can explore the potential of these systems, and your vision can become a reality. Get in contact with us to discover how to revolutionize your business operations and services.
Frequently Asked Questions
Is ChatGPT a Large Language Model?
Yes, ChatGPT is an example of a large language model. It is based on the Generative Pretrained Transformer architecture and can generate human-like text based on the input it receives. Building a ChatGPT plugin allows you to create a custom solution with the capabilities of large language models in understanding and producing natural language.
How much data is needed to train a large language model?
The data needed to train an LLM can vary depending on its intended complexity and scope. Usually, these models undergo training using datasets ranging from hundreds of gigabytes to several terabytes of text. Those criteria help in building a more accurate and unbiased model. Those criteria help in building a more accurate and unbiased model.
How long does it take to create a large language model?
The timeframe for building and training a large language model depends on several factors:
- the complexity of the model;
- the volume of data;
- the computational resources available.
For example, a more basic LLM could be developed and trained in a matter of weeks to a few months. Meanwhile, a model like GPT-4 may take multiple years from conception to deployment.
Are large language models only used in the tech industry?
While the tech industry is a major user of LLMs, their application extends far beyond. They find applications in various fields, for example:
- in healthcare for patient data analysis;
- in finance for market prediction;
- in customer service for chatbots;
- in education for personalized learning tools;
- in creative industries for content generation.
What is the primary use of a large language model?
The primary use of an LLM is to process and generate human language, mimicking our speech and writing. It includes language translation, content creation, summarization, question answering, and conversational agents. Their ability to comprehend human-like text makes them versatile tools in different domains. The goal is to enable effective and natural interaction between computers and humans through language.
How about to rate this article?





6 ratings • Avg 4.7 / 5
Written by: